-
[Pintos] Project 1 : Thread(스레드) - Advanced Scheduler (mlfqs)프로젝트/Pintos 2021. 5. 12. 15:06
자 이제 스레드의 마지막 미션인 Advanced Scheduler 를 구현해보도록 하자. Advanced Scheduler 는 Pintos 도큐먼트 Appendix B 에 기록되어 있는 4.4BSD Scheduler 와 같은 맥락의 스케줄러를 구현하도록 요구한다. 4.4BSD Scheduler 는 Multi-Level Feedback Queue Scheduler 의 구성이며, 이를 줄여서 pintos 의 코드에서는 mlfqs 로 나타나 있다. 4.4BSD 스케줄러의 상세한 내용은 전에 다룬 포스트가 있으니 자세한 이해를 원한다면 아래 링크에서 읽어보길 바란다. (recent_cpu, load_avg 값의 계산식을 분석하는 부분이 매우 흥미롭다.)
[Pintos] 4.4BSD 스케줄러(4.4BSD Scheduler) - niceness, priority, recent_cpu, load_avg, fixed-point real arithmetic
멀티스레드 프로그램에서는 구조가 상이한 여러 스레드들이 함께 존재한다. 어떤 스레드는 다수의 I/O 요청을 처리하지만 복잡한 연산 작업은 없을 수 있으며, 어떤 스레드는 I/O 요청 없이 다수
poalim.tistory.com
Why mlfqs?
이전까지 구현한 priority scheduler 는 그 실행을 오직 priority 에만 맡기기 때문에 priority 가 낮은 스레드들은 CPU 를 점유하기가 매우 어렵고 이로 인하여 평균반응시간(Average response time) 은 급격히 커질 가능성이 있다. 물론 priority donation 을 통하여 priority 가 높은 스레드들이 실행되는 데 필요한 스레드는 priority 의 보정을 받지만, 이마저도 받지 못하는 스레드가 존재할 가능성도 매우 크다. Advanced Scheduler 는 이러한 문제를 해결하고 average response time 을 줄이기 위해 multi-level feedback queue 스케줄링 방식을 도입한다. 이 스케줄링 방식의 특징은 크게 두 가지가 있다.
- Priority 에 따라 여러 개의 Ready Queue 가 존재한다. (Multi-level)
- Priority 는 실시간으로 조절한다. (Feedback)
필자는 이 중에서 2번의 특징에 집중하여 advanced scheduler 를 구현해 보려고 한다. 1번 특징에 따르면, pintos 의 priority 는 0~63 의 범위를 가지므로 64개의 ready queue 를 만들고 이 중 가장 높은 priority 의 ready queue 안에서 round-robin 방식의 스케줄링을 하는 것이지만, 이미 앞선 과제들을 통하여 구현한 스케줄러에서 priority 에 따른 실행은 만족시켰으므로 굳이 1번 특징은 새로 도입하지 않고 2번 특징에 따라 각 스레드의 priority 를 조정하면 알아서 가장 높은 priority 를 가진 스레드가 실행될 것이다.
작동방법
pintos document 에서는 일반 priority scheduler 와 advanced scheduler 중 무엇을 적용할 지 사용자가 선택하도록 요구한다. pintos 를 실행시킬 때 '-mlfqs' 옵션을 넣어주면 advanced scheduler 를 적용하여 kernel 을 작동시키게 된다. 잠깐 살펴보고 가자.
/* threads/init.c */ static char ** parse_options (char **argv) { ... else if (!strcmp (name, "-mlfqs")) thread_mlfqs = true; ... }pintos 의 작성시 '-mlfqs' 옵션이 들어오면 thread_mlfqs 가 true 값을 가지도록 구현되어 있다. 이 값은 <thread.h> 에 정의되어 있다.
/* threads/thread.h */ extern bool thread_mlfqs;이제 thread_mlfqs 가 true 일 때는 advanced scheduler 를, false 일 때는 기존 스케줄러를 사용하도록 구현하면 된다.
Niceness, Priority, Recent_cpu, Load_avg
priority 를 계산하는 데 필요한 각 값들에 대한 자세한 설명은 맨 위에서 언급한 4.4BSD Scheduler 포스트를 참고하도록 하고, 여기서는 간단하게 구현에 필요한 특징들만을 짚고 넘어가도록 한다.
우선적으로 알아두어야 하는 특징은 niceness, priority, recent_cpu 는 각 스레드별로 존재하는 고유 값이고, load_avg 는 시스템에 하나의 값으로 존재한다는 것과, niceness, priority 는 정수값을 갖고 recent_cpu, load_avg 는 실수값을 갖는다는 것이다.
Niceness
- NICE_MIN : -20, NICE_MAX : +20
- NICE_DEFAULT : 0
- 이 값이 클수록 CPU time 을 다른 스레드에게 양보하는 정도가 크다. -> priority 가 낮아진다.
Priority
- PRI_MIN : 0, PRI_MAX : +63
- PRI_DEFAULT : 31
- priority = PRI_MAX - (recent_cpu / 4) - (nice * 2)
- 매 4 tick 마다 모든 스레드의 priority 를 재계산한다.
recent_cpu
- 실수 값을 가진다.
- 스레드가 최근에 얼마나 많은 CPU time 을 사용했는지를 나타내는 값이다.
- 이 값이 클수록 최근에 더 많은 CPU 를 사용했음을 의미하므로 우선순위는 낮아진다.
- RECENT_CPU_DEFAULT : 0
- recent_cpu = (2 * load_avg) / (2 * load_avg + 1) * recent_cpu + nice
- 매 tick 마다 running 스레드의 recent_cpu 값이 1 증가한다. (idle 스레드가 아닐 때)
- 매 1 초마다 모든 스레드의 recent_cpu 값을 재계산한다.
load_avg
- 실수 값을 가진다.
- 최근 1분 동안 수행 가능한 스레드의 평균 개수를 나타낸다.
- 이 값이 크면 recent_cpu 값은 천천히 감소(priority 는 천천히 증가)하고, 작으면 recent_cpu 값이 빠르게 감소(priority 는 빠르게 증가)한다.
- 이유는 수행 가능한 스레드의 평균 개수가 많을 때는 모든 스레드가 골고루 CPU time 을 배분받을 수 있도록 이미 사용한 스레드의 priority 가 천천히 증가하여야 하고, 평균 개수가 적을 때는 조금 더 빠르게 증가해도 모든 스레드가 골고루 CPU time 을 배분받을 수 있기 때문이다.
- LOAD_AVG_DEFAULT : 0
- load_avg = (59/60) * load_avg + (1/60) * ready_threads, (ready_threads 는 ready + running 상태의 스레드의 개수)
- 매 1 초마다 load_avg 값을 재계산한다.
Fixed-point arithmetic
위에서 알 수 있듯이 priority, nice 는 정수 값을, recent_cpu, load_avg 는 실수 값을 가진다. 여기서 문제가 하나 생기는데, 부동 소수점 연산은 복잡한 연산을 다루기 때문에 kernel 을 느리게 만들 가능성이 있다. 이에 따라 pintos kernel 은 부동소수점 연산을 지원하지 않으며 이로 인하여 kernel 에서 위에 나열한 식들의 직접적인 계산은 불가하다. 이를 해결하기 위해 fixed-point 연산을 다루어야 할 필요가 있다.
fixed-point 방식에 대한 자세한 설명 역시 4.4BSD Scheduler 포스트에 적어놓았다. 간단하게 얘기하자면, 총 32bit 중에서 1 bit(sign), 17 bit(정수부), 14 bit(소수부) 로 적용하여 실수를 int 형식으로 표현할 수 있도록 하는 것이다. 한 가지만 예를 들어보자. 만약 recent_cpu 가 2.75 라는 값을 가진다면 이 값은 fixed-point 로는 아래와 같이 나타낼 수 있다.
[0 (sign bit +) 00000000000000010 (정수부 2) 11000000000000 (소수부 0.75)] (소수부의 각 비트는 2^(-1), 2^(-2), ... )
= [00000000000000001011000000000000]
= 45056
이러한 과정을 거쳐서 int recent_cpu = 45056 이라는 정수형으로 값이 저장된다. 이렇게 fp(fixed-point) 로 표현된 값들은 올바른 연산 값을 얻기 위해서 연산 시 특수한 보정 행위를 거쳐야 한다. pintos document 의 Appendix B.6 에 이에 대한 식이 기술되어 있다.

fixed-point 의 연산 (pintos document) 우리가 가장 먼저 구현해야 하는 부분이다. Advanced Scheduler 의 모든 계산에서 fp 연산이 필요하므로 위의 연산식을 구현해둔다.
/* thread/fixed_point.h */ #define F (1 << 14) #define INT_MAX ((1 << 31) - 1) #define INT_MIN (-(1 << 31)) int int_to_fp (int n) { return n * F; } int fp_to_int (int x) { return x / F; } int fp_to_int_round (int x) { if (x >= 0) return (x + F / 2) / F; else return (x - F / 2) / F; } int add_fp (int x, int y) { return x + y; } int sub_fp (int x, int y) { return x - y; } int add_mixed (int x, int n) { return x + n * F; } int sub_mixed (int x, int n) { return x - n * F; } int mult_fp (int x, int y) { return ((int64_t) x) * y / F; } int mult_mixed (int x, int n) { return x * n; } int div_fp (int x, int y) { return ((int64_t) x) * F / y; } int div_mixed (int x, int n) { return x / n; }각 연산식을 구현하기 위해 threads 폴더에 fixed_point.h 라는 헤더파일을 새로 만든 후 thread.c 에서 include 하여 사용하였다. 각 함수는 위의 연산식을 나타내는 그림의 식들을 같은 순서로 코드로 구현한 것이다. 몇 가지 자잘한 설명을 덧붙여보겠다. 모든 함수를 이해하였다면 넘어가도 좋다.
- F 는 fixed point 1 을 나타낸다. (0 00000000000000001 00000000000000)
- INT_MAX 은 (0 11111111111111111 11111111111111), INT_MIN 은 (1 00000000000000000 00000000000000). (잘 모르겠다면 2의 보수(2's complement) 표현법을 찾아보라.)
- 매개변수 x, y 는 fixed-point 형식의 실수이고, n 은 정수를 나타낸다. 모든 mixed 연산에서 n 은 두 번째 파라미터로 들어오게 한다.
- int fp_to_int_round () 에서 F / 2 는 fixed point 0.5 를 뜻한다. 0.5 를 더한 후 버림하면 반올림이 된다.
- int mult_fp () 에서 두 개의 fp 를 곱하면 32bit * 32bit 로 32bit 를 초과하는 값이 발생하기 때문에 x 를 64bit 로 일시적으로 바꿔준 후 곱하기 연산을 하여 오버플로우를 방지하고 계산 결과로 나온 64bit 값을 F 로 나눠서 다시 32bit 값으로 만들어 준다. (div_fp 도 마찬가지)
구현
우선 새로운 자료구조를 추가한다. nice, recent_cpu 를 thread 구조체에 추가한다.
/* threads/thread.h */ #define PRI_MAX 63 #define NICE_DEFAULT 0 #define RECENT_CPU_DEFAULT 0 #define LOAD_AVG_DEFAULT 0 struct thread { ... int nice; int recent_cpu; ... };새로운 변수를 추가하면 초기화도 꼭 신경을 써주어야 한다.
/* threads/thread.c */ static void init_thread (struct thread *t, const char *name, int priority) { ... t->nice = NICE_DEFAULT; t->recent_cpu = RECENT_CPU_DEFAULT; ... }thread.c 에서는 fp 연산을 할 수 있도록 위에서 만든 fixed_point.h 파일을 include 하고 load_avg 를 global 변수로 선언하고 초기화까지 해준다.
/* thread/thread.c */ #include "threads/fixed_point.h" int load_avg; void thread_start (void) { ... load_avg = LOAD_AVG_DEFAULT; ... }다음은 priority 를 계산하는 함수를 만들어주어야 한다.
/* threads/thread.c */ void mlfqs_calculate_priority (struct thread *t) { if (t == idle_thread) return ; t->priority = fp_to_int (add_mixed (div_mixed (t->recent_cpu, -4), PRI_MAX - t->nice * 2)); }mlfqs_calculate_priority () 함수는 특정 스레드의 priority 를 계산하는 함수이다. idle_thread 의 priority 는 고정이므로 제외하고, fixed_point.h 에서 만든 fp 연산 함수를 사용하여 priority 를 구한다. 계산 결과의 소수부분은 버림하고 정수의 priority 로 설정한다.
/* threads/thread.c */ void mlfqs_calculate_recent_cpu (struct thread *t) { if (t == idle_thread) return ; t->recent_cpu = add_mixed (mult_fp (div_fp (mult_mixed (load_avg, 2), add_mixed (mult_mixed (load_avg, 2), 1)), t->recent_cpu), t->nice); }mlfqs_calculate_recent_cpu () 함수는 스레드의 recent_cpu 값을 계산하는 함수이다. fp 연산으로 인해 다소 복잡해보일 수 있다.
/* threads/thread.c */ void mlfqs_calculate_load_avg (void) { int ready_threads; if (thread_current () == idle_thread) ready_threads = list_size (&ready_list); else ready_threads = list_size (&ready_list) + 1; load_avg = add_fp (mult_fp (div_fp (int_to_fp (59), int_to_fp (60)), load_avg), mult_mixed (div_fp (int_to_fp (1), int_to_fp (60)), ready_threads)); }mlfqs_calculate_load_avg () 함수는 load_avg 값을 계산하는 함수이다. load_avg 값을 스레드 고유의 값이 아니라 system wide 값이기 때문에 idle_thread 가 실행되는 경우에도 계산하여 준다. ready_threads 는 현재 시점에서 실행 가능한 스레드의 수를 나타내므로 ready_list 에 들어있는 스레드의 숫자에 현재 running 스레드 1개를 더한다. (idle_thread 는 실행 가능한 스레드에 포함시키지 않음).
이제 각 값들이 변하는 시점에 수행할 함수들을 만들어보자. 이 값들이 변하는 시점은 3 경우가 있었다.
- 1 tick 마다 running 스레드의 recent_cpu 값 + 1
- 4 tick 마다 모든 스레드의 priority 재계산
- 1 초마다 모든 스레드의 recent_cpu 값과 load_avg 값 재계산
/* threads/thread.c */ void mlfqs_increment_recent_cpu (void) { if (thread_current () != idle_thread) thread_current ()->recent_cpu = add_mixed (thread_current ()->recent_cpu, 1); } void mlfqs_recalculate_recent_cpu (void) { struct list_elem *e; for (e = list_begin (&all_list); e != list_end (&all_list); e = list_next (e)) { struct thread *t = list_entry (e, struct thread, allelem); mlfqs_calculate_recent_cpu (t); } } void mlfqs_recalculate_priority (void) { struct list_elem *e; for (e = list_begin (&all_list); e != list_end (&all_list); e = list_next (e)) { struct thread *t = list_entry (e, struct thread, allelem); mlfqs_calculate_priority (t); } }맨 위부터 차례대로 현재 스레드의 recent_cpu 의 값을 1 증가시키는 함수, 모든 스레드의 recent_cpu 를 재계산 하는 함수, 모든 스레드의 priority 를 재계산 하는 함수이다. 이제 각 함수를 해당하는 시간 주기마다 실행되도록 timer_interrupt 함수를 바꾸어주면 된다. <devices/timer.c> 에 있는 timer_interrupt 함수에서 일정 시간마다 tick 을 1 씩 증가시켜 주고 있다. 여기에 조건을 달아주자.
/* devices/timer.c */ static void timer_interrupt (struct intr_frame *args UNUSED) { ticks++; thread_tick (); if (thread_mlfqs) { mlfqs_increment_recent_cpu (); if (ticks % 4 == 0) { mlfqs_recalculate_priority (); if (ticks % TIMER_FREQ == 0) { mlfqs_recalculate_recent_cpu (); mlfqs_calculate_load_avg (); } } } thread_awake (ticks); }mlfqs 옵션이 들어왔을 때에만 advanced scheduler 가 작동할 수 있도록 if 문으로 묶고 각 시간에 맞게 priority, recent_cpu, load_avg 값의 조정이 실행되게 하였다. TIMER_FREQ 값은 1초에 몇 개의 ticks 이 실행되는지를 나타내는 값으로 thread.h 에 100 으로 정의되어 있다. 이에 따라 pintos kernel 은 1 초에 100 ticks 가 실행되고 1 ticks = 1 ms 를 의미한다.
한 가지 더 신경써주어야 하는 것은 lock_acquire (), lock_release () 함수에서 구현해주었던 priority donation 을 mlfqs 에서는 비활성화시켜주어야 한다. mlfqs 스케줄러는 시간에 따라 priority 가 재조정되므로 priority donation 을 사용하지 않는다.
/* threads/synch.c */ void lock_acquire (struct lock *lock) { if (thread_mlfqs) { sema_down (&lock->semaphore); lock->holder = thread_current (); return ; } ... } void lock_release (struct lock *lock) { lock->holder = NULL; if (thread_mlfqs) { sema_up (&lock->semaphore); return ; } ... }또한 mlfqs 스케줄러에서는 priority 를 임의로 변경할 수 없기 때문에 thread_set_priority () 함수 역시 비활성화 시켜야 한다.
/* threads/thread.c */ void thread_set_priority (int new_priority) { if (thread_mlfqs) return; ... }마지막으로 pintos 의 선언만 되어 있고 비어있는 아래 함수들을 채워주자.
/* threads/thread.c */ void thread_set_nice (int); int thread_get_nice (void); int thread_get_load_avg (void); int thread_get_recent_cpu (void);각 값들의 변경 시에는 인터럽트의 방해를 받지 않도록 인터럽트를 비활성화 해야 한다.
/* threads/thread.c */ void thread_set_nice (int nice UNUSED) { // 현재 스레드의 nice 값을 새 값으로 설정 enum intr_level old_level = intr_disable (); thread_current ()->nice = nice; mlfqs_calculate_priority (thread_current ()); thread_test_preemption (); intr_set_level (old_level); } int thread_get_nice (void) { // 현재 스레드의 nice 값을 반환 enum intr_level old_level = intr_disable (); int nice = thread_current ()-> nice; intr_set_level (old_level); return nice; } int thread_get_load_avg (void) { // 현재 시스템의 load_avg * 100 값을 반환 enum intr_level old_level = intr_disable (); int load_avg_value = fp_to_int_round (mult_mixed (load_avg, 100)); intr_set_level (old_level); return load_avg_value; } int thread_get_recent_cpu (void) { // 현재 스레드의 recent_cpu * 100 값을 반환 enum intr_level old_level = intr_disable (); int recent_cpu= fp_to_int_round (mult_mixed (thread_current ()->recent_cpu, 100)); intr_set_level (old_level); return recent_cpu; }recent_cpu, load_avg 의 getter 는 pintos document 의 지시대로 100 을 곱한 후 정수형으로 만들고 반올림하여 반환하도록 하였다. 정수형 반환값에서 소수점 2째 자리까지의 값을 확인할 수 있도록 하는 용도인 것 같다.
결과
자 이제 구현이 마무리 되었으니 make check 를 돌려보도록 하자.
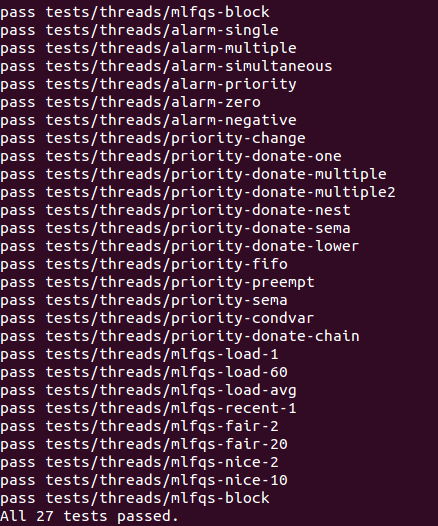
드디어 Project 1 - Thread 의 모든 테스트를 통과하였다!! pintos 프로젝트를 진행하면서 구현 과정 보다도 구현을 위한 background 공부에서 너무 많은 것을 배우고 느끼고 있다. 컴퓨터의 동작을 하나하나 밑바닥부터 조각내어 뜯어보는 느낌이라 이해하기 어려웠던 부분도 있지만, 모든 조각이 감탄스러웠고 이 조각들이 합쳐져서 kernel 로 동작하는 것을 보니 컴퓨터와 프로그램이 얼마나 위대한 발명품인지 온몸으로 느낄 수 있었다. 앞으로 남은 projects 들을 진행하는 것도 잔뜩 기대중이니 다음 포스트도 기다려주세요!
'프로젝트 > Pintos' 카테고리의 다른 글