-
[Pintos] Project 1 : Thread(스레드) Background- 진행흐름, Kernel thread, 코드분석, Registers, assembly, switch.S 분석프로젝트/Pintos 2021. 4. 9. 17:32
이 포스트에서는 본격적인 프로젝트에 들어가기 위해 꼭 필요한 개념들을 잡아두기 위해 여러 가지 배경 지식들을 설명한다. 이는 pintos kernel 에서 threads 의 기본적인 흐름도, 범용 레지스터 개념, struct thread 의 구조, 주어진 코드 분석(thread.h, thread.c, switch.h, switch.S) 등이 포함된다.
진행흐름
전 포스트에서 살펴봤다시피 pintos 의 loader 는 우리를 init.c 의 main 함수로 가져다놓는다. 이 main 함수를 살펴보면 여러 초기화 작업 후에 가장 먼저 나오는 작업은 thread 의 시작이다. 코드에서 한 번 살펴보자.
/* thread/init.c */ /* Pintos main program. */ int main(void){ ... thread_init(); ... ... thread_start(); ... ... thread_exit(); }한 가지 유의해야 할 점은, 여기서 말하는 thread 란 우리가 평소에 보아왔던 user thread 와는 다른 것이라는 것이다. pintos 에서 user thread 는 user_thread 라고 표시되어 있으며 계속해서 언급되는 thread 는 항상 kernel thread 를 말한다. 그렇다면 kernel thread 의 개념부터 알아보도록 하자. thread 와 관련된 함수들은 <thread.h>, <thread.c> 에 작성되어 있다.
Kernel thread
/* thread/thread.c */ /* Function used as the basis for a kernel thread. */ static void kernel_thread (thread_func *function, void *aux) { ASSERT (function != NULL); intr_enable (); /* The scheduler runs with interrupts off. */ function (aux); /* Execute the thread function. */ thread_exit (); /* If function() returns, kill the thread. */ }이 함수가 thread 동작의 전부이다. 보면 알겠지만 사실상 하는 것이라고는 function 하나를 실행시키는 것이 전부이다. 파라미터를 보면, thread_func *function 은 이 kernel 이 실행할 함수를 가르키고, void *aux 는 보조 파라미터로 synchronization 을 위한 세마포 등이 들어온다. 여기서 실행시키는 function 은 이 thread 가 종료될때가지 실행되는 main 함수라고 생각할 수 있다. 즉, 이 function 은 idle thread 라고 불리는 thread 를 하나 실행시키는데, 이 idle thread 는 하나의 c 프로그램에서 하나의 main 함수 안에서 여러 함수호출들이 이루어지는 것처럼, pintos kernel 위에서 여러 thread 들이 동시에 실행될 수 있도록 하는 단 하나의 main thread 인 셈이다. 우리의 목적은 이 idle thread 위에 여러 thread 들이 동시에 실행되도록 만드는 것이다.

kernel_thread 의 동작 위의 init.c 의 main 코드에서 보면, thread_init() 에서 thread 에 들어가야 하는 여러 정보들을 초기화 해준 후 thread_start() 에서 idle thread 를 만들어주면서 본격적으로 thread 를 시작한다.
/* thread.c */ void thread_start (void) { /* Create the idle thread. */ struct semaphore idle_started; sema_init (&idle_started, 0); thread_create ("idle", PRI_MIN, idle, &idle_started); /* Start preemptive thread scheduling. */ intr_enable (); /* Wait for the idle thread to initialize idle_thread. */ sema_down (&idle_started); } static void idle (void *idle_started_ UNUSED) { struct semaphore *idle_started = idle_started_; idle_thread = thread_current (); sema_up (idle_started); for (;;) { /* Let someone else run. */ intr_disable (); thread_block (); asm volatile ("sti; hlt" : : : "memory"); } }thread_start() 에서 thread_create 을 하는 순간 idle thread 가 생성되고 동시에 idle 함수가 실행된다. idle thread 는 여기서 한 번 schedule 을 받고 바로 sema_up 을 하여 thread_start() 의 마지막 sema_down 을 풀어주어 thread_start 가 작업을 끝내고 run_action() 이 실행될 수 있도록 해주고 idle 자신은 block 된다. idle thread 는 pintos 에서 실행 가능한 thread 가 하나도 없을 때 이 wake 되어 다시 작동하는데, 이는 CPU 가 무조건 하나의 thread 는 실행하고 있는 상태를 만들기 위함이다.
Thread 진행흐름
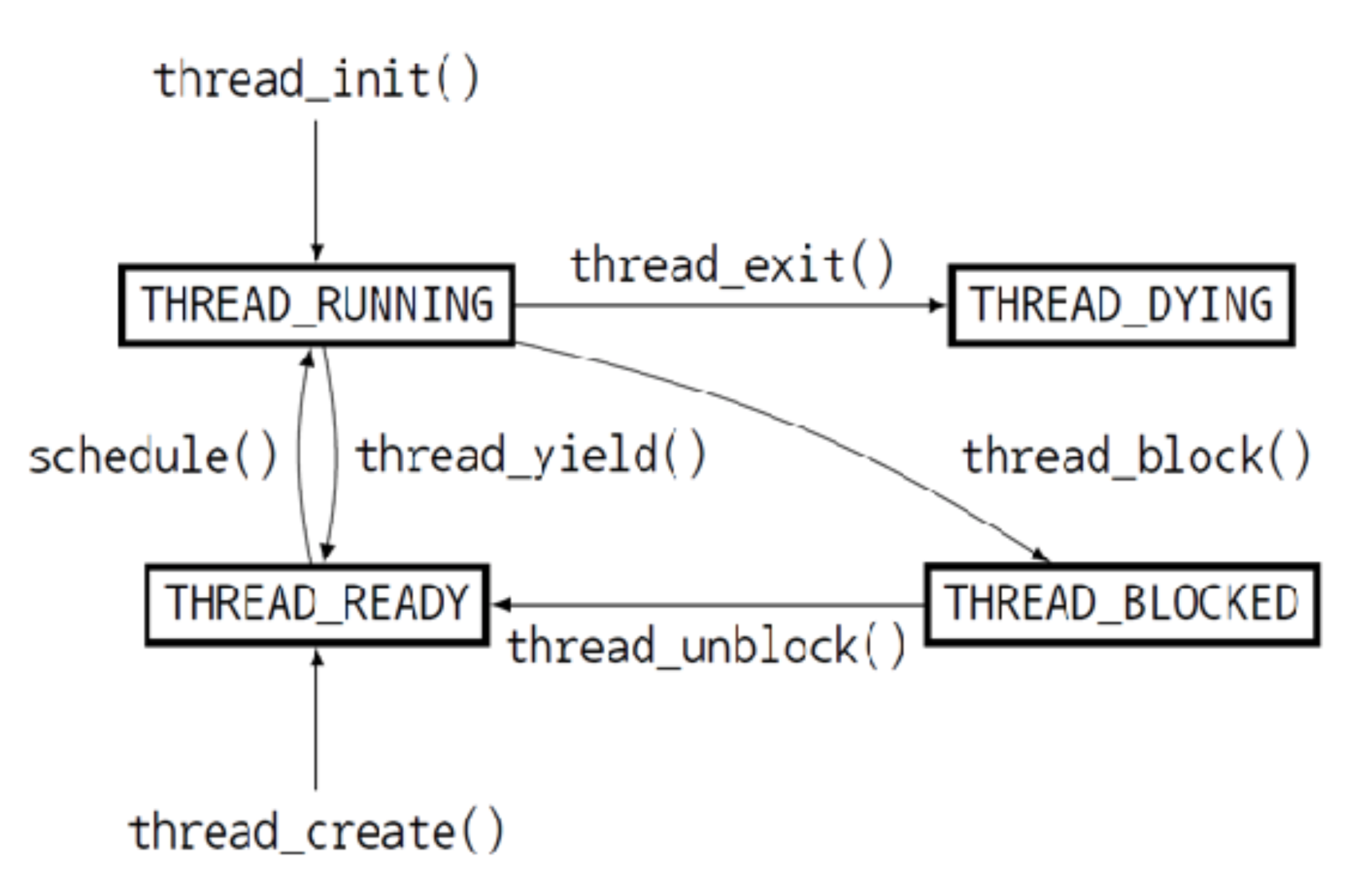
Thread 는 RUNNING, READY, BLOCKED, DYING 의 4가지 상태를 가진다.
- THREAD_RUNNING : 현재 실행중인 스레드를 말하고 한 번에 하나의 스레드만 running 상태를 가질 수 있다.
- THREAD_READY : 실행될 준비가 되어 실행을 기다리는 상태이며, 현재 실행중인 스레드가 실행을 멈추면 이 상태에 있는 스레드 중 하나가 실행 상태로 들어간다. 이 상태에 있는 스레드들은 READY QUEUE 에 들어가 관리된다.
- THREAD_BLOCKED : 말 그대로 멈춰서 아직 실행 불가능한 상태이며, thread_unblock() 을 통해 실행 가능한 상태가 되면 THREAD_READY 상태가 되어 ready queue 에 들어간다.
- THREAD_DYING : 스레드의 실행이 모두 끝나고 종료된 상태이다.
위의 흐름에서 ready queue 에 스레드들을 넣고 뺄 때의 순서를 정하는 것이 scheduling 의 주된 작업이라고 할 수 있다. 현재 pintos 는 round-robin 방식으로 구현되어 있고, 이는 어떤 스레드가 THREAD_READY 상태가 되어 ready queue 에 들어갈 때 queue 의 맨 뒤로 들어가고 next_thread_to_run() 에서 다음 running 상태가 될 스레드를 고를 때는 queue 의 맨 앞의 스레드를 골라서 queue 에 들어온 순서대로 실행되는 방식이다.
Scheduling
하나의 스레드를 실행시키다가 다른 스레드로 CPU 의 소유권을 넘겨야 할 때 scheduling 이 일어난다. 이 scheduling 이 일어나는 순간은 위의 스레드 흐름도에서 볼 수 있듯이 thread_yield(), thread_block(), thread_exit() 함수가 실행될 때이다. 이 함수들은 현재 실행중인 스레드에서 호출해주어야 하는데, 실행중인 스레드가 이 함수들을 실행시키지 않고 계속 CPU 소유권을 가지는 것을 방지하기 위하여 추가로 한 가지 장치가 있다.
/* devices/timer.c */ static void timer_interrupt (struct intr_frame *args UNUSED) { ticks++; thread_tick (); }/* thread/thread.c */ void thread_tick (void) { struct thread *t = thread_current (); /* Update statistics. */ if (t == idle_thread) idle_ticks++; #ifdef USERPROG else if (t->pagedir != NULL) user_ticks++; #endif else kernel_ticks++; /* Enforce preemption. */ if (++thread_ticks >= TIME_SLICE) intr_yield_on_return (); }timer 인터럽트는 매 tick 마다 ticks 라는 변수를 증가시킴으로서 시간을 잰다. 이렇게 증가한 ticks 가 TIME_SLICE 보다 커지는 순간에 intr_yield_on_return() 이라는 인터럽트가 실행되는데, 이 인터럽트는 결과적으로 thread_yield() 를 실행시킨다. 즉 위의 scheduling 함수들이 호출되지 않더라고 일정 시간마다 자동으로 scheduling 이 발생한다.
이제 scheduling 함수가 어떻게 작동하는지를 살펴보자. 사실 이 함수의 작동을 정확하게 이해하는 것이 thread system 의 가장 핵심이다. scheduling 함수는 thread_yield(), thread_block(), thread_exit() 함수 내의 거의 마지막 부분에 실행되어 CPU 의 소유권을 현재 실행중인 스레드에서 다음에 실행될 스레드로 넘겨주는 작업을 한다. 코드를 한 번 살펴보자.
// <thread/thread.c> static void schedule (void) { struct thread *cur = running_thread (); struct thread *next = next_thread_to_run (); struct thread *prev = NULL; ASSERT (intr_get_level () == INTR_OFF); ASSERT (cur->status != THREAD_RUNNING); ASSERT (is_thread (next)); if (cur != next) prev = switch_threads (cur, next); thread_schedule_tail (prev); }여기서부터는 설명의 편의를 위해 현재 실행중인 thread 를 thread A 라고 하고, 다음에 실행될 스레드를 thread B 라고 하겠다. *cur 은 thread A, *next 는 next_thread_to_run() 이라는 함수(ready queue 에서 다음에 실행될 스레드를 골라서 return 함. 지금은 round-robin 방식으로 고른다.)에 의해 thread B 를 가르키게 되고, *prev 는 thread A 가 CPU 의 소유권을 thread B 에게 넘겨준 후 thread A 를 가리키게 되는 포인터다.
- ASSERT (intr_get_level () == INTR_OFF) : scheduling 도중에는 인터럽트가 발생하면 안 되기 때문에 INTR_OFF 상태인지 확인한다.
- ASSERT (cur->status != THREAD_RUNNING) : CPU 소유권을 넘겨주기 전에 running 스레드는 그 상태를 running 외의 다른 상태로 바꾸어주는 작업이 되어 있어야 하고 이를 확인하는 부분이다.
- ASSERT (is_thread (next)) : next_thread_to_run() 에 의해 올바른 thread 가 return 되었는지 확인한다.
그 후 새로 실행할 스레드가 정해졌다면 switch_thread (cur, next) 명령어를 실행한다. 이 함수는 <thread/switch.S> 에 assembly 언어로 작성되어 있다. 이 함수가 사실상 핵심이기에 내용을 뜯어보기 전에 이 코드를 해석하려면 범용 레지스터와 assembly 언어에 대한 기본적인 이해가 필요할 것 같다.
범용 레지스터
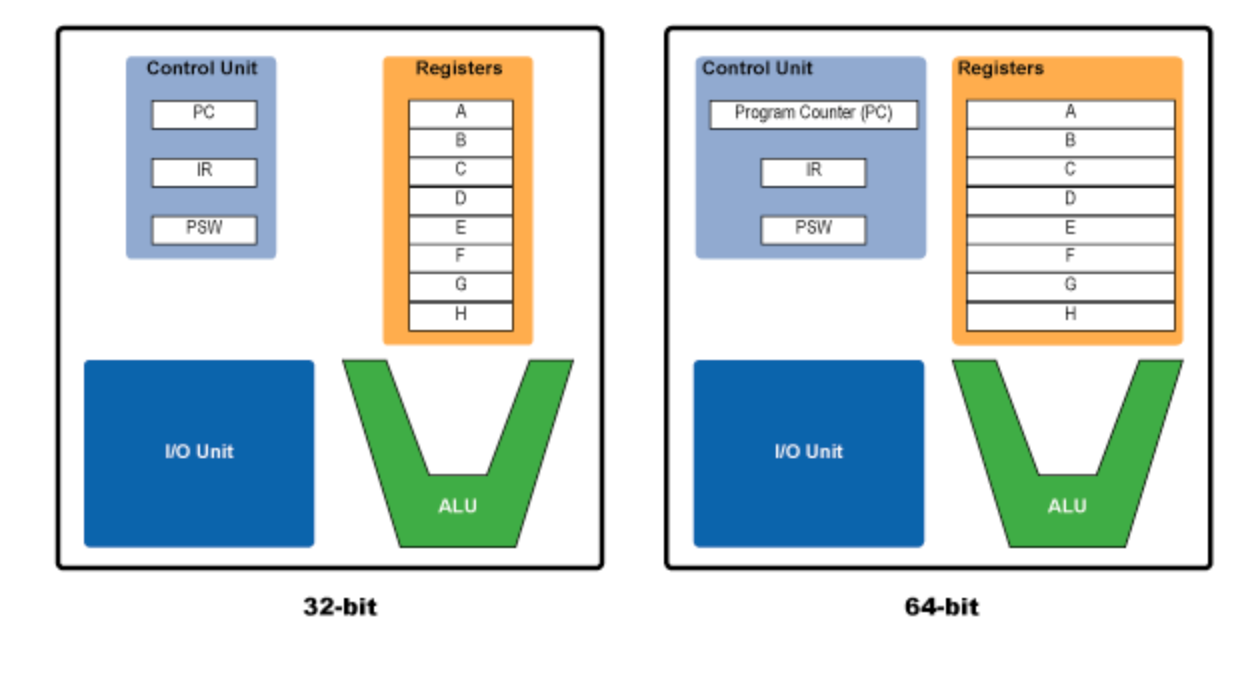
CPU 의 구성 우리가 사용하는 CPU 는 위 그림처럼 구성되어 있다. Control Unit 은 CPU 를 제어하는 장치이고, I/O Unit 은 입출력 장치를 다루고, ALU 는 여러 연산을 처리하는 장치이다. 그 외에 CPU 에도 Register 라는 아주 작은 저장소들이 있는데, 이들은 CPU 가 데이터에 접근하는 가장 빠른 방법을 제공한다. x86 장치에서 CPU 는 (그 밖에도 다른 레지스터들이 존재하지만) 다음의 8개의 범용 레지스터가 CPU 의 효율적인 일처리를 위해 각기 용도에 맞게 설계되어 있다.
- EAX(Extended Accumulator Register) : 산술연산 또는 함수의 리턴 값 저장. 이 레지스터의 값을 살펴보면 함수의 리턴 여부, 리턴 값을 알 수 있다.
- EDX(Extended Data Register) : EAX 의 확장 개념으로 복잡한 연산의 추가 데이터 저장을 위해 사용된다.
- ECX(Extended Counter Register) : 반복적으로 수행되는 연산에 사용되는 카운터 값이 저장된다. 항상 감소되는 방향으로 설계되어 있다.
- ESI(Extended Source Index) : 데이터 연산에서 데이터의 source, 즉 입력 데이터의 앖 혹은 입력 스트림의 위치를 나타낸다. 주로 Read 작업을 위해 사용된다.
- EDI(Extended Destination Index) : 데이터 연산에서 데이터의 destination, 즉 연산의 결과값의 위치를 나타낸다. 주로 Write 작업을 위해 사용된다.
- ESP(Extended Stack Pointer) : 스택의 가장 높은(최근 PUSH된) 위치를 가리킨다. 함수 호출 시 리턴 주소가 가장 마지막에 PUSH 되므로 함수 호출 직후 ESP 는 보통 리턴 주소를 가리킨다.
- EBP(Extended Base Pointer) : ESP 와 반대로 스택의 시작점을 가리킨다.
- EBX : 특정 용도 X, 추가적인 저장소로써 사용된다.
- EIP : 현재 실행중인 명령의 주소를 가리킨다.
다음 내용의 설명 중 위의 내용을 중간중간 참조하여 설명할 것이기 때문에 이정도로만 정리해두고 넘어가도록 하자.
각 스레드는 하나의 page(4KB) 에 저장된다. 그 구조는 <thread/thread.h> 에 저장되어 있고, 아래와 같다.
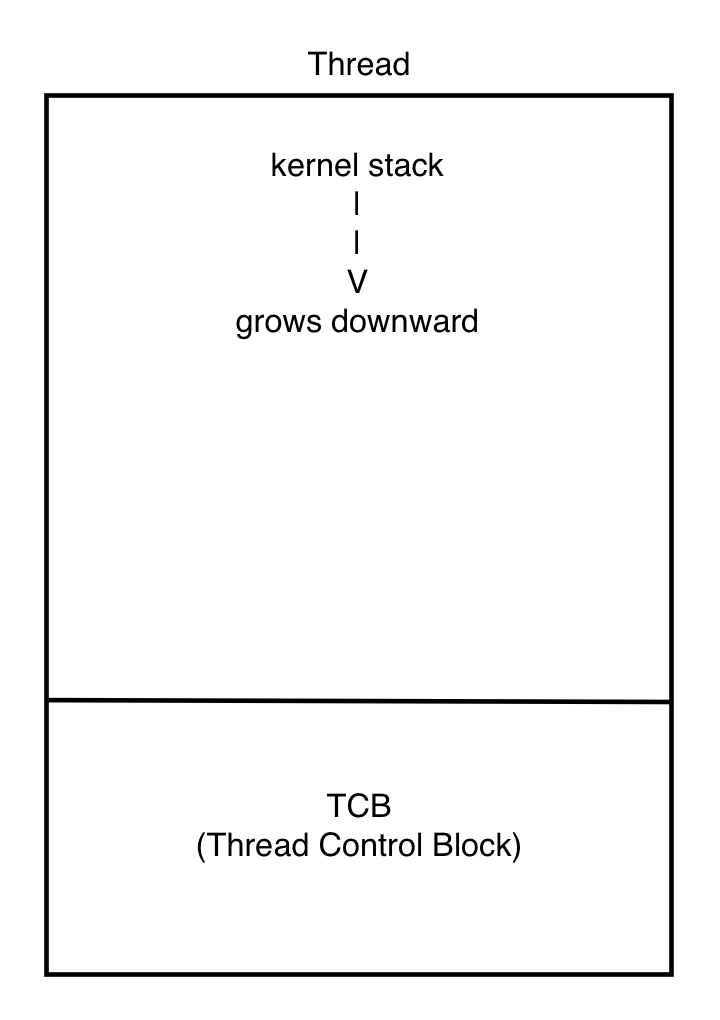
Thread Structure 스레드는 스레드의 정보를 저장하는 TCB 영역과, 여러 정보를 저장하는 kernel stack 영역으로 나누어져 있고, TCB 영역은 offset 0 에서 시작하여 1KB 를 넘지 않는 작은 크기를 차지하고, stack 영역은 나머지 영역을 차지하고 TCB 영역을 침범하지 않기 위해 위에서부터 시작하여 아래 방향으로 저장된다.
TCB 영역의 구성은 다음과 같다.
struct thread { /* Owned by thread.c. */ tid_t tid; /* Thread identifier. */ enum thread_status status; /* Thread state. */ char name[16]; /* Name (for debugging purposes). */ uint8_t *stack; /* Saved stack pointer. */ int priority; /* Priority. */ struct list_elem allelem; /* List element for all threads list. */ /* Shared between thread.c and synch.c. */ struct list_elem elem; /* List element. */ #ifdef USERPROG /* Owned by userprog/process.c. */ uint32_t *pagedir; /* Page directory. */ #endif /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };여기서 *stack 이라고 표현된 포인터가 중요한데, 실행중인 스레드 thread A 에서 scheduling 이 일어나면, 현재 CPU 가 실행중이던 상태, 즉 현재 CPU 의 Register 들에 저장된 값들을 이 stack 에 저장한다. 후에 다시 thread A 가 실행되는 순간에 이 stack 의 값들이 다시 CPU 의 Register 로 로드되어 실행을 이어갈 수 있게 된다. 이 stack 은 TCB 위의 부분 kernel stack 의 특정 부분에 저장되기 때문에 *stack 포인터는 kernel stack 의 특정 부분을 가리킨다.
자, 이 내용을 가지고 <switch.S> 의 코드를 분석해보도록 하자.
.globl switch_threads .func switch_threads switch_threads: # Save caller's register state. # # Note that the SVR4 ABI allows us to destroy %eax, %ecx, %edx, # but requires us to preserve %ebx, %ebp, %esi, %edi. See # [SysV-ABI-386] pages 3-11 and 3-12 for details. # # This stack frame must match the one set up by thread_create() # in size. pushl %ebx pushl %ebp pushl %esi pushl %edi # Get offsetof (struct thread, stack). .globl thread_stack_ofs mov thread_stack_ofs, %edx # Save current stack pointer to old thread's stack, if any. movl SWITCH_CUR(%esp), %eax movl %esp, (%eax,%edx,1) # Restore stack pointer from new thread's stack. movl SWITCH_NEXT(%esp), %ecx movl (%ecx,%edx,1), %esp # Restore caller's register state. popl %edi popl %esi popl %ebp popl %ebx ret .endfunc보다시피 코드는 어셈블리어로 이루어져 있다. 어셈블리어를 모두 설명하긴 지나치므로 여기서 알아야 할 내용만 간단히 짚고 넘어가겠다.
Assembly 언어
- 레지스터 이름의 앞에 % 기호를 붙여서 레지스터를 나타낼 수 있다.
- (%eax) 와 %eax 는 엄연히 다른 역할을 한다. 괄호가 붙으면 해당 레지스터의 값이 아니라, 해당 레지스터에는 가상 메모리에서의 메모리 주소가 들어있고, 해당 메모리 주소의 값을 나타낸다. 즉 포인터이다.
- 예를들어, %eax 에 0x0000CD 라는 값이 있고, 현재 진행중인 프로세스의 가상 메모리의 0x0000CD 주소에 8 이라는 값이 저장되어 있다면, %eax = 0x0000CD, (%eax) = 8 이 된다.
- assembly 언에서 사용되는 상수의 경우에는 기본적으로 해당 주소의 메모리 값을 나타낸다. 해당 상수 자체를 나타내기 위해서는 '$' 을 앞에 붙인다.
- $8 : 상수 8 을 나타냄
- 8 : 메모리의 0x8 주소에 있는 값을 나타냄
- add, sub, mov 등의 명령어 뒤에 붙는 b, w, l 등은 변수의 크기를 나타낸다.
- movb : byte 단위의 명령
- movw : word(4byte) 단위의 명령
- movl : double word(8byte) 단위의 명령
- 괄호의 활용
- 항이 2개인 경우 : (%eax, %ebx) => (%eax + %ebx) => %eax 레지스터의 값 + %ebx 레지스터의 값 의 결과가 가리키는 메모리 주소의 값
- 항이 3개인 경우 : (%eax, %ebx, 3) => (%eax + %ebx * 3) => 마지막 항은 두번째 항에 곱하기로 적용
- 괄호 앞에 상수 : 8(%eax) => (8 + %eax) => 상수를 더한 결과가 가리키는 주소의 값
- mov, push, pop 명령어의 용도
- movl A B : A 의 값을 B 에 저장한다.
- pushl A : A 의 값을 stack 에 저장, (ex. pushl %eax => %eax 레지스터의 값이 stack 에 저장됨)
- popl A : stack 에서 값을 하나 제거하면서 A 에 저장, (ex. popl %eax => stack 의 맨 위의 값을 %eax 레지스터에 저장함)
- ret : return
우선 scheduling() 함수에서 switch_thread 함수의 호출부터 보자.
- prev = switch_threads (cur, next);
위와 같이 cur (thread A), next (thread B) 를 파라미터로 받으며 함수가 호출된다. 함수가 호출되면 kernel stack 에는 함수의 파라미터와 return 주소가 차례로 저장된다. 즉 아래와 같은 상태가 된다.
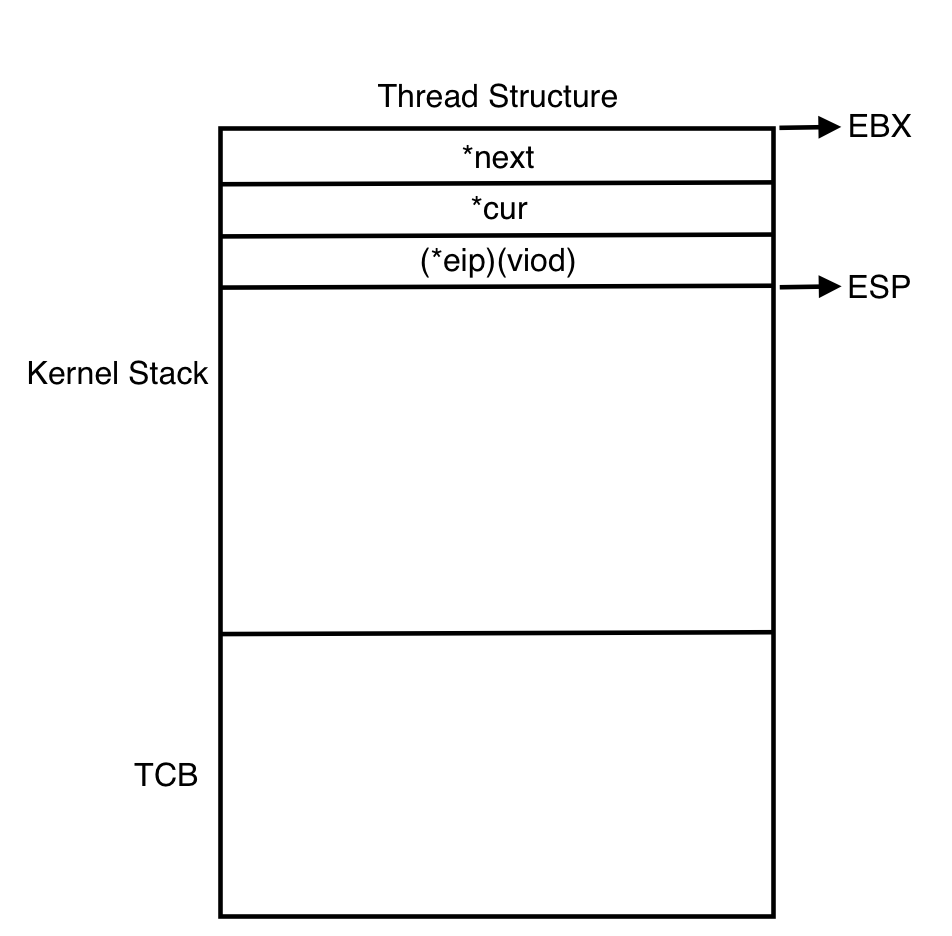
switch_threads 의 코드에서 pushl %ebx ~ pushl %edi 를 실행하면 현재 스택포인터(ESP) 에서부터 값들이 push 된다.
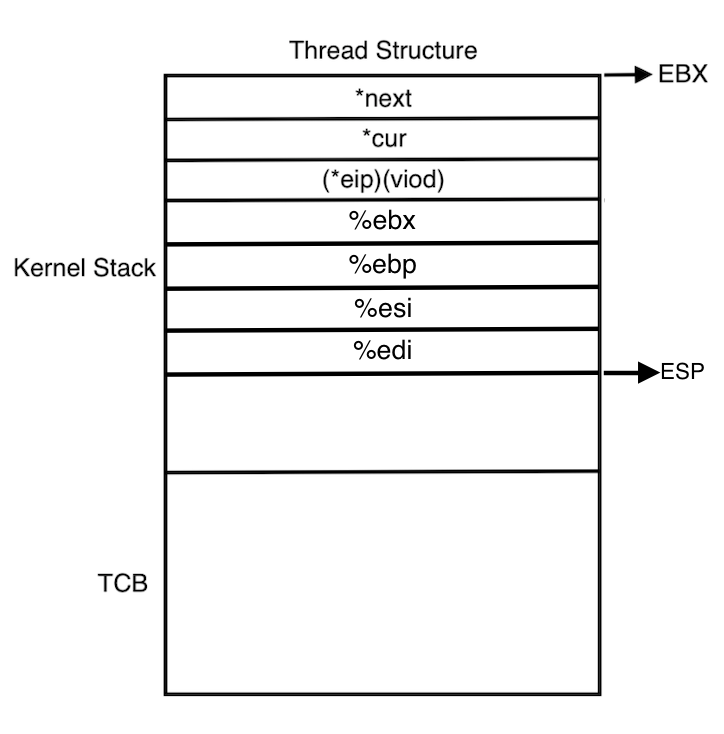
이렇게 kernel stack 이 모두 채워지고 이 stack frame 의 모습은 <thread/switch.h> 에서 아래와 같이 찾아볼 수 있다.
struct switch_threads_frame { uint32_t edi; /* 0: Saved %edi. */ uint32_t esi; /* 4: Saved %esi. */ uint32_t ebp; /* 8: Saved %ebp. */ uint32_t ebx; /* 12: Saved %ebx. */ void (*eip) (void); /* 16: Return address. */ struct thread *cur; /* 20: switch_threads()'s CUR argument. */ struct thread *next; /* 24: switch_threads()'s NEXT argument. */ };오른쪽 주석으로 달린 0, 4, 8, ... 은 offset 을 말하고, 기준은 ESP 이다.
자 이제 다음 줄을 분석해보자.
# Get offsetof (struct thread, stack). .globl thread_stack_ofs mov thread_stack_ofs, %edx이 부분인데, 여기서 thread_stack_ofs 가 뭔가 싶을 수 있다. 이 값은 thread 의 시작 주소와 stack 포인터가 있는 주소 사이의 간격(offset) 을 나타내고 <thread.c> 의 마지막줄에 아래와 같이 구현되어 있다.
/* Offset of `stack' member within `struct thread'. Used by switch.S, which can't figure it out on its own. */ uint32_t thread_stack_ofs = offsetof (struct thread, stack);여기서 나타내는 stack 포인터를 kernel stack 이라고 생각하면 큰일난다. 당연히 TCB 안에 있는 *stack 을 나타내는 것이다.

mov thread_stack_ofs %edx 를 하였으므로 이 값을 %edx 레지스터에 저장한다. 이 값은 thread 주소와 더하여 stack 포인터의 위치를 알아내는 데 사용된다.
다음을 살펴보자.
# Save current stack pointer to old thread's stack, if any. movl SWITCH_CUR(%esp), %eax movl %esp, (%eax,%edx,1)SWITCH_CUR 이 생소하다. 이것은 <switch.h> 에서 찾아볼 수 있다.
#define SWITCH_CUR 20 #define SWITCH_NEXT 24SWITCH_CUR, SWITCH_NEXT 는 20, 24 를 나타내는 상수라는 걸 알 수 있다. 그러면 위의 식은 아래와 나타낼 수 있다.
- movl 20(%esp), %eax => movl (20 + %esp), %eax
20 + esp 은 위의 thread 그림에서 볼 수 있듯이 *cur 의 값이 저장되어 있는 주소이다. 헷갈린다면 위에 잠깐 언급한 switch_thread_frame 을 참고하자. 즉 kernel stack 에서 *cur 에 저장되어 있는 값을 %eax 로 저장한다는 의미이다. *cur 에는 처음 switch_thread(cur, next) 함수의 호출 때, 현재 running thread, 즉 thread A 의 주소를 받아와 저장했었다. 즉, 현재 실행중인 스레드 thread A 의 주소를 %eax 레지스터에 저장한다.
- movl %esp, (%eax, %edx, 1)
이것은 현재 %esp 의 값을 (%eax + %edx * 1) 가 가르키는 메모리 주소에 저장하라는 명령이다. 현재 %esp 에는 kernel stack 의 맨 아래부분의 주소가 저장되어 있다. %eax 는 thread_stack_ofs, %edx 는 thread A 의 시작주소 가 저장되어 있으므로 이 두 값을 더하면 thread A 의 TCB 부분의 stack 포인터 위치를 알 수 있다고 위에 언급했었다. 즉 이 stack 포인터 자리에 %esp 에 있는 값이 입력되므로 stack 포인터가 위의 kernel stack 영역의 맨 아래 주소를 가리키게 된다. 그림으로 보면 아래와 같다.
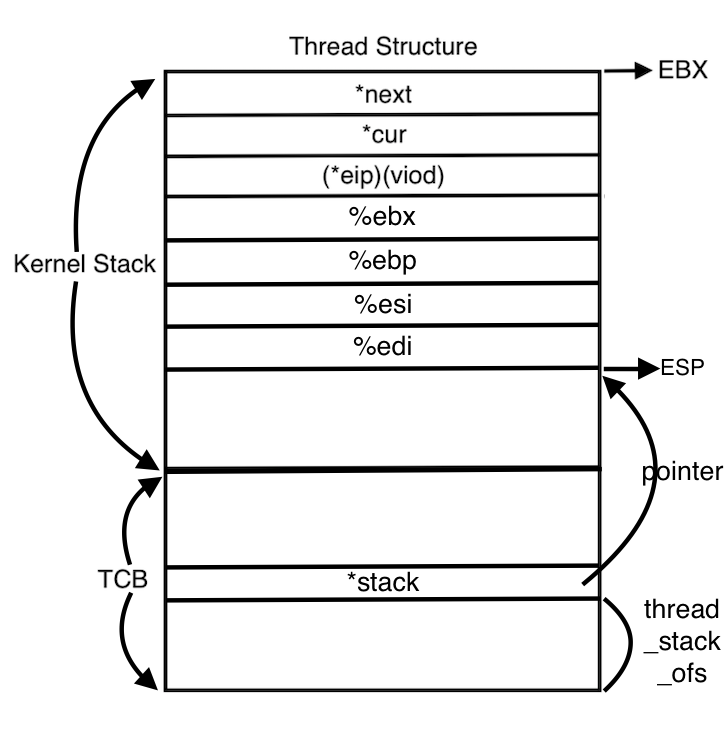
이제 거의 다 왔다. 다음 코드 부분을 살펴보자.
# Restore stack pointer from new thread's stack. movl SWITCH_NEXT(%esp), %ecx movl (%ecx,%edx,1), %espSWITCH_NEXT(%esp) 는 SWITCH_CUR(%esp) 에서 본 것처럼 이번에는 kernel stack 영역의 *next 를 나타내고, 이 값을 %ecx 레지스터에 저장한다.
다음 줄의 명령은 (%ecx + %edx * 1) 의 메모리 주소의 값을 %esp 에 저장한다. %ecx 는 다음에 실행할 스레드 thread B 의 시작 주소, %edx 는 thread_stacks_ofs 이므로, 이는 다음에 실행할 스레드 thread B 의 stack 포인터 주소를 %esp 레지스터에 저장함을 말한다. 여기까지 마친 후 각 레지스터에 들어있는 값을 아래 표로 정리하였다.
%edx thread_stacks_ofs %eax SWITCH_CUR(%esp) : 현재 실행중인 thread A 의 주소(*cur) %esp 다음에 실행할 thread B 의 stack 포인터가 가르키는 값 -> thread B 의 kernel stack 영역의 top의 주소 %ecx SWITCH_NEXT(%esp) : 다음에 실행할 thread B 의 주소(*next) 여기까지 실행되면 마법같은 일이 생긴다. 방금전까지 실행되던 레지스터들의 값(%ebx, %ebp, %esi, %edi) 는 모두 thread A 의 구조 안에 저장하였고, %esp 가 thread A 의 kernel stack 영역의 top 을 가리키던 것이 이제 thread B 의 kernel stack 영역의 가장 아래부분(top) 을 가리키게 되면서 자연스럽게 CPU 의 제어가 thread B 로 넘어왔다.
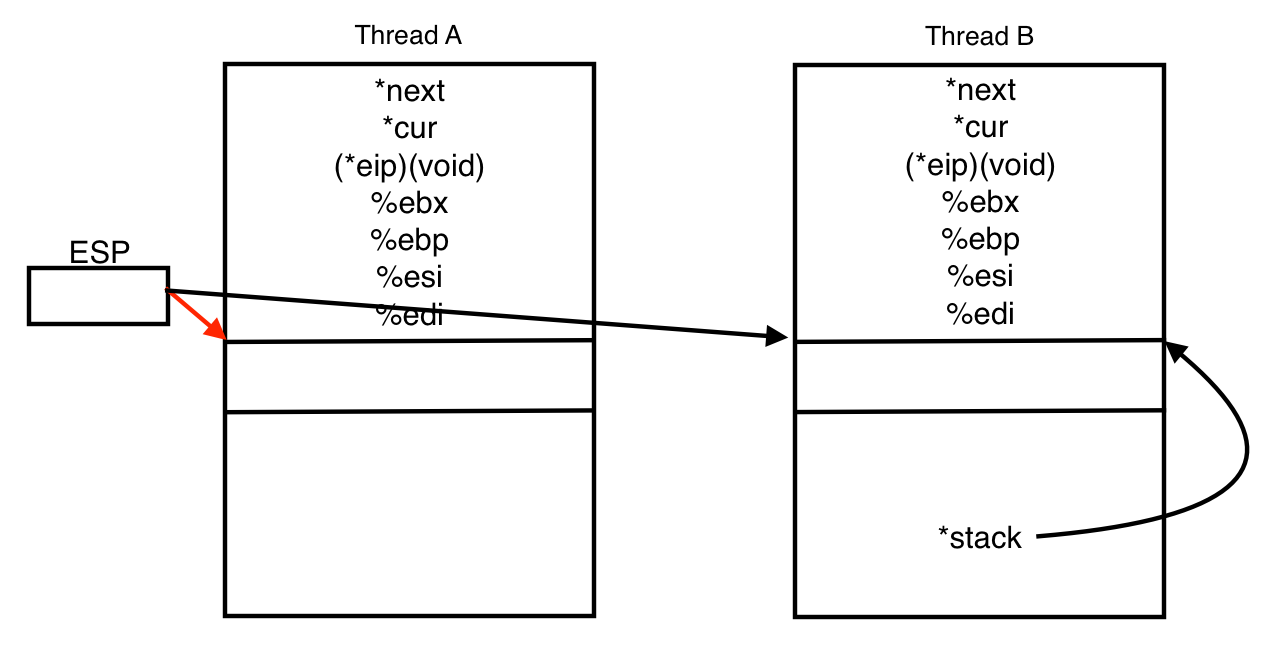
여기서 popl %edi ~ popl %ebx 의 명령이 수행되는데, 이제 thread B 로 CPU 의 제어가 넘어갔으므로 thread B 의 kernel stack 영역에 저장되어 있던 edi ~ ebx 의 값이 CPU 의 레지스터로 load 된다. 이후의 실행은 thread B 의 제어 아래에서 일어난다.
그 후 마지막으로 ret 명령어가 실행되어 return 이 되는데, 이 때 return 은 %eax 의 값을 읽어온다고 하였다(%eax 범용 레지스터의 용도가 리턴값을 저장하는 것임). eax 레지스터의 값은 바꾼 적이 없기 때문에 thread A 가 running 상태일 때 저장한 값이 그대로 들어있다. 위에 표를 보면 thread A 의 주소가 저장되어 있다고 쓰여있다. 즉, 이 return 명령이 실행되는 시점은 thread B 의 제어 아래에서 return 되지만 thread A 가 반환되고, 이제는 prev 스레드가 되어버린 thread A 의 주소를 뱉는다. 이 때문에 switch_thread() 의 반환값은 thread A 의 주소가 되고 schedule() 에서 prev = switch_thread(cur, next); 로 호출했기 때문에 prev 가 전에 실행중이던 스레드인 thread A 의 주소를 가리키게 된다.
이제 Pintos project 1 - Thread 를 시작하기 위한 배경지식은 모두 설명하였다. 다음 포스트에서는 실제 구현을 해본다.
Reference
thread status : h2oche.github.io/2019/03/12/pintos-guide-1/
범용 CPU 레지스터 : thinkpro.tistory.com/107?category=562773
'프로젝트 > Pintos' 카테고리의 다른 글